凯发官网 AI 产物司理手记: 一份能跟模子团队 battle 的评测框架(上)

AI产物的评测法度究竟应该由谁来界说?本文深度见识AI客服名目中模子团队与业务方的评测法度之争,揭示现存评测体系的三苟简命劣势,并给出包含12项硬性方针和5大多轮对话维度的全新评测框架。从致命失实一票否决到多轮会话标的达成度,这套让业务能看懂、能扣分、能复现的评测体系,正在再行界说AI产物的得手法度。

一个AI功能到底什么时候算”作念好了”?作念AI产物的东谈主,早晚会被这个问题绊一跤。
准确率?92%听起来很高,但用户问十句答错一句,依然够投诉一整天的了。调回率?88%看着也行,但漏掉的那12%若是全是用户最思问的高频问题呢?F1、BLEU、ROUGE?这些方针在paper里很漂亮,落到一个具体的业务功能上,没东谈主能径直告诉你谜底。
更扎心的是:模子团队拿着一张评测论述说”方针达标了,不错上线”,业务侧翻几条真实对话,第一反应是”这都能上线?”。双方都合计对方不暖和,但谁也劝服不了谁。
这件事的实质,是评测体系自己有问题——不是模子答得不够好,是这把尺子根柢没量在用户着实预防的所在。
而评测体系这把尺子由谁定、量什么、怎么扣分,决定了你这个AI产物的天花板。
布景:最近在作念AI客服名目,底下通盘的例子都来自这个场景。但写出来的东西不适度于客服——任何需要”业务判断模子横蛮”的AI落地名目,逻辑是重复的。
一、先看当今的评测有多”热心”
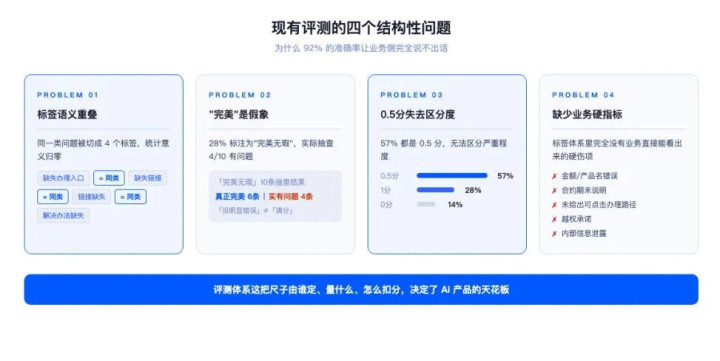
最近一批的标注表(单轮对话),标签TOP5如下:
1、圆善无暇2、短缺办理进口3、问官答花4、无效反问5、模子拒答
打分散播更夸张:0.5分占57%,1分占28%,0分只占14%。
我把看出的问题列了一下:
一、”圆善无瑕”28%是假象。
我抽了10条所谓圆善无瑕,至少4条都属于”没明白失实是以打满分”,但内部其实没说办理进口、没阐发用户身份、用了”提出相关客服”这种甩锅话术。没扣分不等于满分。
二、0.5分占57%等于失去折柳度。
要么是0.5(小缝隙),要么是0(明白错),评测没法告诉模子团队”哪些0.5比另一些0.5更严重”。
三、都备莫得业务硬方针。
标签里莫得“金额/产物名失实”“合约期未阐发”“未给出可点击办理旅途”这种业务一眼能看出来的硬伤项。
更要命的是多轮,整张表唯有”回答后果0/1″+”模子/数据/业务”三个原因桶。莫得任何一个字段是多轮对话专有的——落魄文经受了莫得?指代消解对了莫得?用户半途换意图认出来了莫得?这些一个都没评。
是以我跟模子团队battle时其实很被迫:他们说”按现存法度你看准确率多高”,我只可说”我嗅觉不太行”。“嗅觉”是赢不了”准确率”的。得换一把尺子。
二、新评测框架:让业务能看懂、能扣分、能复现
我再行捋了一下,评测一条AI客服回话,实质上是在回答三个问题:
1)它说对了吗?
(事实正确性)
2)它处治问题了吗?
(任务完成度)
ag最新app下载官方网站3)用户能不成坐窝用上?
(可操作性/业务闭环)
这三层自下而上,越往上业务侧越预防。模子团队民俗只评第一层,是以才会出现”准确率高但业务不舒坦”的撕扣。
2.1单轮评测:分层维度+业务硬扣项
按照”难度/业务场景/客户问题/评估重心”四列建了一张测试集骨架和示例:
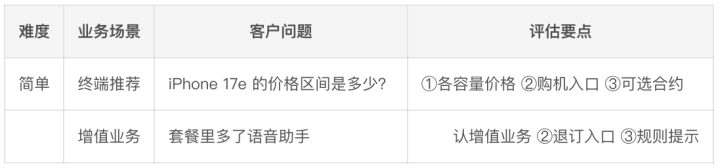
关键点:评估重心是事先界说的、可逐项打钩的。不是评测时再进展,是出题时就锁死。这么模子团队没法逃避——你托福的谜底有莫得遮掩这3个重心,业务一眼能看出来。
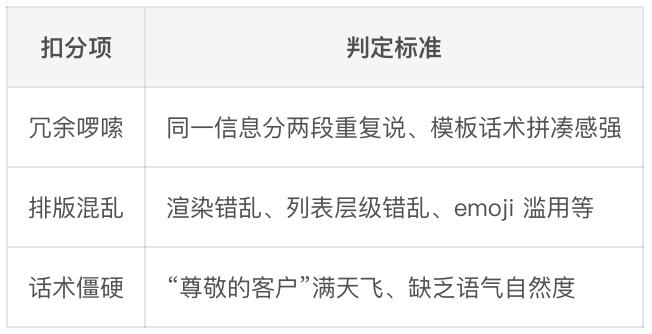
在此基础上,我把扣分项再行并吞成3层12项:
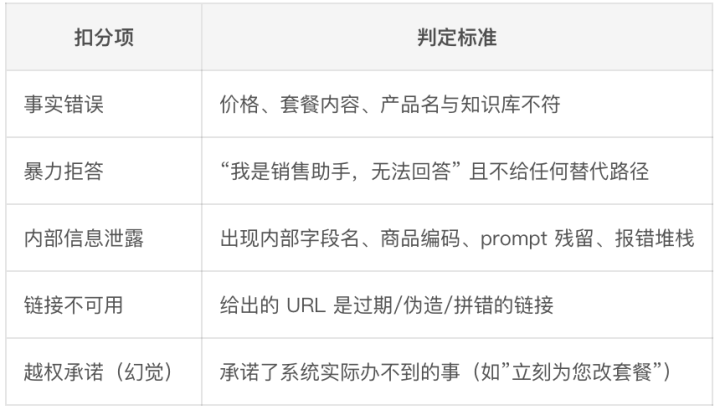
L1·致命失实(径直0分,一票否决)
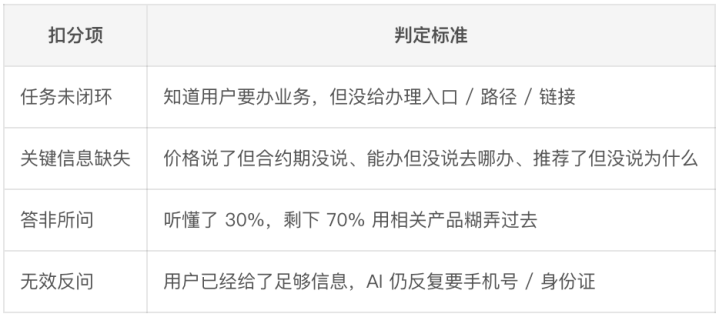
L2·严重不达标(扣0.5分,需复核能否上线)
L3·体验问题(扣0.2~0.3分,可上线但需迭代)
这套维度跟面前评测最大的区别有两个:
L1是一票否决。
模子团队不成用”100条里唯有6条暴力拒答”这种平均数糊已往——只须有6条致命失实,这版就不玉成量。
L2/L3分开记。
L2是阻止上线的问题,L3是迭代项。跟模子battle时,我不错说”L1+L2加权不达标,上线先停”,比一句”嗅觉不行”硬气一万倍。
2.2多轮评测:5个多轮专有维度
多轮是面前评测的重灾地。我看了那102条多轮标注,发现大部分扣分根由都是”问官答花””意图错”——这些方针其实是单轮方针的延长,莫得任何一个评在了”多轮”自己。
多轮对话和单轮的中枢区别是:它有历史、有指代、有状况、有切换。我提了5个多轮专属维度:
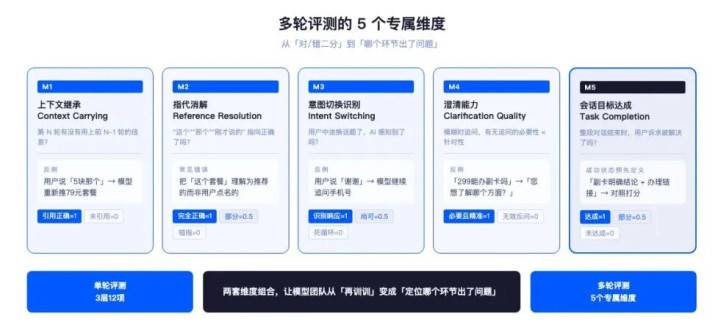
M1·落魄文经受(ContextCarrying)
第N轮的回话有没灵验向前边N-1轮的信息?
举个真实例子(多轮表第5~7条,青海):用户先说”你把我套餐改一下”,再说”最低廉的”,凯发娱乐(K8)官方网站再说”5块阿谁”——这里指代的是「最低廉的套餐里5块阿谁」。模子若是在第三轮再行推了一遍79、99元套餐,落魄文经受即是0分。
评分表情:第N轮的回话中,是否正确援用了前N-1轮的至少1个关键实体(产物名/号码/金额/技巧)。0/1二分。
M2·指代消解(ReferenceResolution)
“这个”“阿谁”“刚才说的那款”有莫得正确对应到具体对象?
模子时常把”这个套餐”交融成上一轮系统推选的套餐,而不是用户点名的套餐。打分:都备正确1,部分正确0.5,错指0。
M3·意图切换识别(IntentSwitching)
用户半途换话题了,AI认出来了吗?
举例多轮表第13条(重庆):先报障”连不上采集”,AI提取手机号;用户下一句”谢谢”。AI应识别意图已切换为划定性完毕,而不是陆续追问手机号。打分:识别并反映1,未识别但回话尚可0.5,仍在首肯图死轮回0。
M4·澄澈才略(ClarificationQuality)
用户描画朦胧时,AI问的澄澈问题有莫得价值?
反例:用户问”299不错办副卡吗”,AI反问”请示您是思了解299套餐的哪个方面”——这是无效反问,因为用户依然问得很了了了。打分维度:是否果然需要澄澈(必要性)×澄澈问题问得是否精确(针对性)。
M5·会话标的达成度(TaskCompletion)
整段对话完毕时,用户的诉求被处治了吗?
这是最终极的方针,亦然业务侧最预防但最难量化的。我的作念法是:对每一段多轮对话,事先界说”得手状况”——比如”用户获得了办副卡的明确论断+办理连合”。会话完毕时东谈主工对照得手状况打分(达成1/部分达成0.5/未达成0)。
这五个维度组合下来,多轮评测的颗粒度径直从底本的”对/错”酿成“哪个武艺出了问题”。对模子团队来说,他们也终于能定位优化点——是落魄文丢了?照旧指代错了?照旧兜底太死?而不是依稀地”再训训”。
三、让评测法度自己不错被challenge
这是我最近补的一条原则,单独拎出来说。
每个扣分案例,模子团队都不错质疑,但必须给出对应程序的解读,而不是”我合计这条不该扣”。
比如某条被打了”任务未闭环”,模子团队说”这条用户没明说要办理”。OK,那咱们坐下来看:评估重心里写了”需给出办理进口”吗?若是写了,扣分红立;若是没写,是出题的东谈主锅。程序有问题就改程序,但不成凭个东谈主感受推翻。
这个机制确立起来之后,battle的对象从”东谈主对东谈主”酿成了”程序对程序”。氛围一下就好了好多。
四、我的一些不雅察和黑货
写到这里其实步地论依然说结束。终末讲点更主不雅的东西。
第一,评测权在业务手里,不在模子团队手里。模子团队认真把分数搞上去,但”分数掂量什么”这件事的界说权,必须在业务。
第二,AI产物司理的中枢活儿之一即是界说评测。在大模子落地名目里,评测体系的操办才略>Prompt才略>模子调优才略。Prompt写得好的东谈主好多,能写出一份让模子团队没法甩锅、让业务能复用的评测表的东谈主,少得多。
第三,”准确率”在业务侧场景里险些是个伪方针。因为它默许了”每个问题唯有一个正确谜底”。但真实客服场景里,一个用户问”299能办副卡吗”,正确谜底不是”能”或”不成”——是”能,且这是办理进口,且这是程序辅导”。准确率掂量的是单点正确,业务预防的是任务闭环。这两件事在评测里要分开看。
第四,模子经久会拟合你的评测法度。是以评测法度的健壮性,决定了你这个产物的天花板。一份厄运的评测,会让模子团队把沿路元气心灵优化在错的方进取,浪掷几个月。
评测框架搭好仅仅第一步。着实的问题在于:标结束一堆badcase凯发官网,然后呢?哪些该改常识库、哪些该训模子、哪些其实是兜底战略的问题?这部分我下一篇接着写。